
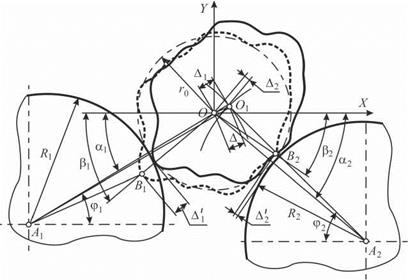
При бесцентровом суперфинишировании заготовка базируется на двух валках, поперечные сечения которых представляют собой окружности радиусами R1 и R2 с центрами в точках А1 и А2 (рис. 6.5). Положение этих окружностей относительно начала системы координат (X О Y) задано углами ai и а2.
Считаем, что при базировании заготовка, описанная уравнением (6.7), стремится занять устойчивое положение на двух валках. При этом заготовка под действием силы тяжести смещается
|
от номинального положения, последовательно перекатываясь по поверхностям валков.
Рис. 6.5. Схема базирования заготовки при бесцентровом суперфинишировании |
Установим точки контакта на основе максимума зазора, выраженного модулем А’ и полярным углом в:
А'(Pi) = {r(Pi +180°)- ri(Pi)} ^max; 1
А2 (р2 ) = {r(360° — р2) — r2 (р2 )} ^ may J.
где r1, r2 — уравнения окружностей левого и правого валков в полярной системе координат.
Проекцию А1 смещения А’ на направление угла а1 находим из треугольника ОА1В1 по теореме косинусов:
(R1 — А1)2 = r12 +(R1 + r0)2 -2r1(R1 + r1)cos(p1 — a1) , (6.9) откуда после преобразований
А1 = R1 — у/r12 + (R1 + r0)2 -2rj(R1 + r)cos(p1 — a). (6.10)
Аналогично находим проекцию Л2 смещения Л^ на направление угла а2 из треугольника ОА2В2:
R2 ~л1 r22 + (R2 + r0)2 — 2r2 (R + r2)cos(p2 — a2). (6.11)
После базирования центр заготовки сместится в точку Оі и расстояние от него до центра левого валка будет равно А1О1 = = R1 + r0 + Ль а до центра правого валка А2О1 = R2 + r0 + Л2. Центр заготовки последовательно движется по левому валку по дуге окружности радиуса А1О1 и по правому валку по дуге окружности радиуса А2О1. Пересечение этих траекторий и будет новым положением центра заготовки О1. Определим координаты точки О1 из совместного решения уравнений данных окружностей в проекциях на оси X и Y:
![]() -(R1 + r0) cos a1 + (R1 + r0 + Л1) cos ф1 = = (R2 + r0) cos a2 — (R2 + r0 + Л2) cos ф2;
-(R1 + r0) cos a1 + (R1 + r0 + Л1) cos ф1 = = (R2 + r0) cos a2 — (R2 + r0 + Л2) cos ф2;
-(R1 + r0) sin a1 + (R1 + r0 + Л1) sin ф1 =
= -(R2 + r0) sin a2 + (R2 + r0 +Л2) sin ф2,
где ф1 и ф2 — углы наклона отрезков А1О1 и А2О1 к оси X (см. рис. 6.5).
В уравнениях (6.12) первые слагаемые в левой и правой частях представляют собой проекции центров окружностей валков, а вторые слагаемые — проекции радиусов траекторий центра заготовки.
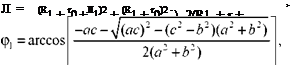 |
|
Решение системы уравнений (6.12) дает выражения для расчета погрешности базирования:
где a = (R2 + r0)cos a2 + (R1 + r0)cos a1;
b = (R2 + r0)sina2 -(R1 + r0)sinaj;
c _ (R2 + ro + A2)2 — (q2 + b2) — (Ri + ro + Ai)2 2( Ri + ro + Ai)
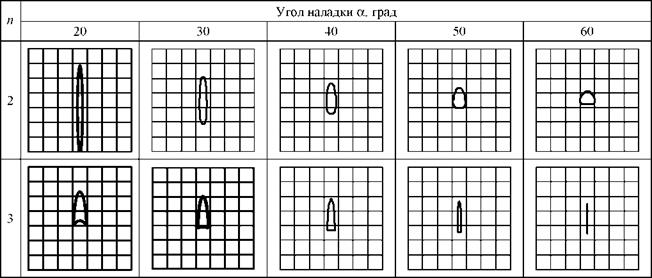
Исследуем траектории движения центра заготовки при ее вращении в зависимости от наладки бесцентрового суперфинишного станка. В табл. 6.1 приведены расчетные траектории центра при одном обороте заготовки со средним радиусом r0 = 8 мм, имеющей отклонение формы в виде 2-, 3-, 4- и 5-й гармоник с амплитудами а2 = а3 = а4 = а5 = 1 мкм.
В качестве оптимизируемого параметра выступает суммарный угол a установки валков. Радиусы валков приняты R1 = R2 = = 62,5 мм и положение их центров А1 и А2 определено через параметры a1, a2 и r0. Так же, как и ранее, начальные фазы гармоник взяты равными нулю и углы установки валков относительно заготовки приняты равными a1 = a2.
Траектории движения центра при бесцентровом суперфинишировании похожи на траектории, полученные при бесцентровом шлифовании. Это объясняется тем, что радиусы валков многократно превышают отклонения формы заготовки и в окрестности точек контакта мало отличаются от прямых.
Для 2-, 3-, 4- и 5-й гармоник рассчитан критерий K точности базирования в зависимости от наладочных углов валков. Результаты расчета представлены в табл. 6.2. Для 2-й гармоники при углах a = 10, 15° и для 3-й гармоники при угле a = 10° имеет место провал заготовки между валками в ряде положений при ее вращении. Поэтому критерий K для указанных случаев не вычислен.
Исследование критерия K показало, что для 2-, 3-, 4-, 5-й гармоник оптимальным углом наладки в диапазоне a = 10… 60° является максимальное значение 60°. Для приведенных примеров при a = 10.60° значение критерия К изменяется от 1,0 до 4,5. По аналогии с бесцентровым шлифованием с поперечной подачей можно предположить, что оптимальные углы наладки располагаются в пределах a = 80.110°, но реализация таких углов на суперфинишном станке невозможна по силовым ограничениям.

|
Траектории движения центра заготовки при бесцентровом суперфинишировании
|
|
п |
Угол наладки а, град |
||||||||||||||||||||||||||||||||||||||||||||
|
20 |
30 |
40 |
50 |
60 |
|||||||||||||||||||||||||||||||||||||||||
|
4 |
|||||||||||||||||||||||||||||||||||||||||||||
|
I |
А |
А |
* |
А |
|||||||||||||||||||||||||||||||||||||||||
|
Е |
н |
И |
|||||||||||||||||||||||||||||||||||||||||||
|
5 |
|||||||||||||||||||||||||||||||||||||||||||||
|
д |
і |
||||||||||||||||||||||||||||||||||||||||||||
|
Л |
1 |
| |
А |
Д |
|||||||||||||||||||||||||||||||||||||||||
|
1 |
1 |
U |
м |
||||||||||||||||||||||||||||||||||||||||||
|
Таблица 6.2 Критерий K при бесцентровом суперфинишировании
|
Для рассчитанного диапазона наладок критерий К принимает значения только больше единицы, что говорит о копировании погрешностей базовой поверхности и наличии тенденции к созданию новых погрешностей. При уменьшении отношения радиусов валков и заготовки наблюдается некоторое уменьшение критерия K. Однако, как будет показано далее, участие в процессе формообразования шлифовального бруска с большой площадью охвата поверхности заготовки создает условия для эффективного исправления погрешностей формы.
При оптимизации процесса бесцентрового суперфиниширования по критерию точности базирования следует учитывать геометрические, кинематические и силовые ограничения. Геометрические ограничения накладываются исходя из расчета профиля валков на этапе профилирования или расчета формообразующей траектории при наладке станка. Ограничения по силовым параметрам имеют нелинейный характер и выявляются при решении задачи силового замыкания контакта.
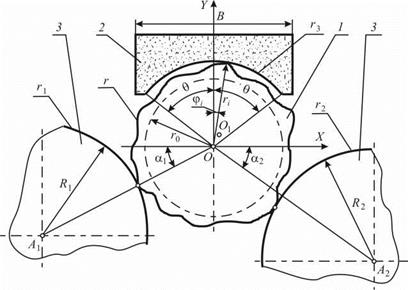
Помимо математической модели базирования, также разработана модель формообразования поперечного сечения заготовок при бесцентровом суперфинишировании. Предложенный подход основан на моделировании процесса съема припуска с учетом погрешностей базирования и изменения натягов в технологической системе. В качестве обобщенного критерия формообразования выступает коэффициент К1 исправления профиля, равный отношению исходного А отклонения от круглости к полученному после имитационной обработки Аі.
Расчетная схема формообразования представлена на рис. 6.6. Заготовка 1 базируется на двух валках 3. Брусок 2 в приработанном состоянии имеет образующую в виде дуги окружности радиуса r3 с углом охвата 20. Значение угла 0 зависит от соотношения ширины бруска, диаметра заготовки и величины приработки шлифовального бруска. Радиус r3 в процессе обработки меняется в пределах половины поля допуска на диаметр заготовки. В рамках предложенной модели это не имеет принципиального значения, поэтому радиус образующей бруска принят постоянным.
|
Рис. 6.6. Схема формообразования при бесцентровом суперфинишировании |
Поперечное сечение заготовки опишем следующим образом:
p
r = r0 +t + Xan cos(«9-9„^ (6.14)
n=2
где t — припуск на сторону.
В процессе обработки стабилизируются натяги в ТС, созданные исходными отклонениями формы заготовки и погрешностями базирования. При определении мгновенных натягов и мгновенных съемов металла приняты следующие допущения. Изменение радиуса заготовки по отношению к номинальному вызывает изменение натягов в ТС и, соответственно, давления шлифовального бруска. При постоянной жесткости резания приращение давления прямо пропорционально приращению снимаемого металла.
Радиальный съем металла 5 в пределах длины контакта заготовки со шлифовальным бруском:
5 = r — r0 +tj — j + %Ar, (6.15)
где j — текущий оборот заготовки (1 < k < m); m — число оборотов заготовки, необходимое для съема припуска t; % — коэффициент, связанный с жесткостью резания.
При расчете величины 5 учитывают только положительные значения, при отрицательных значениях полагают 5 = 0. За j-й оборот заготовки в каждой точке профиля съем металла произойдет только один раз. Съем полного припуска t совершится за m оборотов заготовки.
При каждом текущем обороте заготовки 2jn получаем новый профиль rj, для которого заново рассчитываем погрешности базирования. После изменения угла ф до 2тп заготовку считают обработанной. Окончательный съем металла произойдет на величину, большую, чем исходный припуск t. Это объясняется дополнительным съемом металла из-за изменения натягов в ТС. Исходными данными при моделировании являются: радиус детали r0; параметры профиля п; ап и фп; припуск t; максимальное число т оборотов заготовки при обработке; радиусы валков R1 и R2; ширина В шлифовального бруска; углы а1 и а2 установки валков.
Получив дискретно заданный профиль детали после имитационной обработки, необходимо найти его аналитический эквивалент и определить отклонение от круглости. Если считать, что центры средней окружности детали до и после обработки совпадают с достаточной точностью, то параметры уравнения профиля в виде тригонометрического полинома (6.1) определяют по формулам Бесселя [61], а отклонение от круглости Д1 рассчитывают по стандартной методике [62]. В случае, когда полученное значение К1 меньше требуемого [K1], проводят параметрическую оптимизацию при наличии ограничений. Единообразное математическое представление профиля детали при формообразовании и измерении позволяет проанализировать не только комплексный показатель К1, но и изменение амплитудного состава погрешностей.
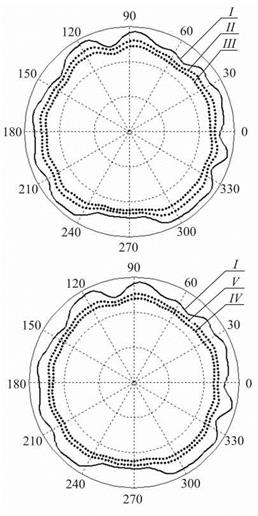
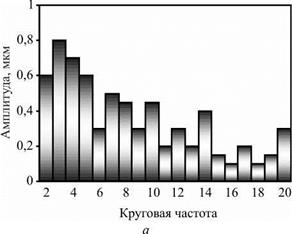
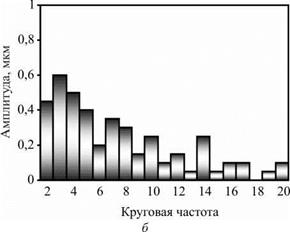
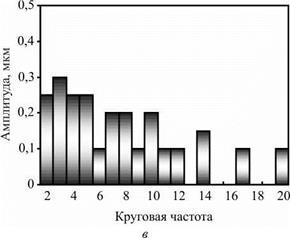
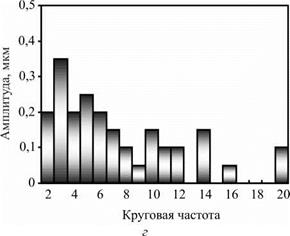
Рассмотрим пример моделирования процесса формообразования при следующих параметрах: r0 = 12 мм; t = 0,004 мм; m = 50; R1 = R2 = 60 мм; B = 12 мм; а1 є [35°; 15°]; а2 є [15°; 35 °]. Результаты представлены на рис. 6.7 в виде поперечных профилей детали: I — исходный; II — после обработки при указанных параметрах; III — после обработки с оптимальными углами контакта (аі = 22°; а2 = 54°); IV — после обработки с увеличенным припуском (t = 0,008 мм); V — после обработки с увеличенной шириной бруска (B = 24 мм). Профили изображены в виде наложенных друг на друга круглограмм с совмещенными центрами, одинаковым радиальным масштабом увеличения и различными средними радиусами записи (для равномерного размещения профилей в зоне записи диаграммы). Амплитуды гармонических погрешностей детали для вариантов I-IV представлены на рис. 6.8.
Исходное отклонение от круглости составило Д = 4,2 мкм. После имитационной обработки для вариантов II—V отклонения от круглости Д1 равны 3,1; 2,2; 1,8; 1,7 мкм, коэффициент К1 исправления профиля равен 1,35; 1,91; 2,33; 2,47 соответственно. Таким образом, увеличению критерия формообразования К1 способствуют: увеличение ширины инструмента, припуска на обработку, а также оптимизация наладочных параметров станка.
|
Рис. 6.7. Расчетные круглограммы деталей |
Анализ результатов моделирования показал, что наибольшее влияние на исправление профиля заготовки оказывают ширина шлифовального бруска и припуск на обработку. Однако наличие жестких технологических ограничений приводит к необходимости поиска других параметров оптимизации. Поэтому наиболее актуальными параметрами при оптимизации процесса формообразования следует считать углы контакта заготовки с валками. По итогам численных экспериментов рекомендована область оптимальных углов контакта, определяемая соотношениями: а < а2 + 5°; а > 15°; аі + а2 < 90°, получившая применение в разработке нового способа суперфиниширования [49].
|
|
|
Рис. 6.8. Амплитудный состав гармонических погрешностей профиля детали: а — вариант I; б — вариант II |
|
|
|
Рис. 6.8. Окончание: в — вариант III; г — вариант IV |
Наладка станков при обработке партии заготовок на основе статистического моделирования
Налаживать бесцентровые суперфинишные станки на обработку одной конкретной заготовки нецелесообразно, а в партии отклонения формы заготовок имеют стохастический характер. Выявить одну доминирующую гармонику не всегда возможно, так как обычно имеются несколько гармоник со сравнительно большими амплитудами.
Для решения подобных задач используется метод статистического моделирования, также называемый методом статистических испытаний Монте-Карло [63]. Он базируется на применении случайных чисел некоторой случайной величины с заданным распределением вероятности. Сущность метода статистического моделирования сводится к построению моделирующего алгоритма, его реализации с помощью программно-технических средств ЭВМ и обработке данных методами математической статистики.
Применительно к наладке станков основная идея метода Монте-Карло заключается в моделировании стохастических входных данных (отклонений формы заготовок), многократной реализации аналитической модели базирования и получении вероятностных характеристик, численные значения которых совпадают с результатом решения детерминированной задачи. В результате получают серию частных значений искомой погрешности базирования, статистическая обработка которых дает сведения о влиянии параметров наладки станка при обработке партии заготовок. Исходные данные о погрешностях формы заготовок получают экспериментальным путем, а законы и параметры распределения рассчитывают по формулам математической статистики. Если количество реализаций модели достаточно велико, то полученные результаты моделирования приобретают статистическую устойчивость и с достаточной точностью принимаются в виде оценок искомых параметров. Моделирующий алгоритм приведен на рис. 6.9.
Исходными данными при моделировании являются: параметры заготовки З (радиус r0, число n гармоник, параметры распределения и границы интервала изменения амплитуд и начальных фаз гармоник), параметры наладки станка (углы базирующих элементов аь а2, радиусы валков Ль R2) и количество m заготовок в партии. Число m заготовок в партии назначают, исходя из трудоемкости моделирования, а не из реального технологического процесса. Очевидно, что с увеличением числа реализаций m возрастает точность и достоверность получаемых статистических оценок.
|
Рис. 6.9. Моделирующий алгоритм наладки станка |
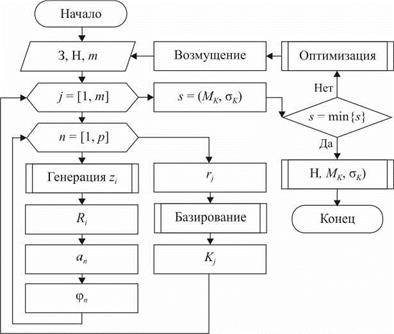
Первый этап моделирования включает генерирование последовательности случайных равномерно распределенных чисел z для каждой заготовки в партии в зависимости от числа гармоник профиля. Полученные числа z преобразуют в требуемый закон распределения для амплитуды at и начальной фазы фг — каждой гармоники. В результате формируют профиль одной заготовки rj.
На втором этапе рассчитывают погрешность базирования для каждой заготовки по аналитической модели и находят критерий точности базирования Kj.
На третьем этапе проводят статистическую обработку критерия K, вычисленного для всех заготовок в партии. В результате получают математическое ожидание Мк и среднеквадратическое отклонение ок для критерия K. Далее проводят оптимизацию по указанным параметрам. Особенность заключается в том, что параметры Мк и ок имеют единый минимум.
Результаты статистического моделирования существенно зависят от качества исходных последовательностей случайных чисел. На практике используют три основных способа генерации случайных чисел: аппаратный, табличный и алгоритмический. Алгоритмический способ генерации случайных чисел наиболее рационален при моделировании на компьютере. Его сущность состоит в том, что равномерно распределенная случайная величина в интервале [0, 1] имеет математическое ожидание m = ‘Л и дисперсию а2 = 1/12. Получить непрерывное распределение на ЭВМ не-
|
2 |
П
у
случайных чисел того же интервала. Такой закон распределения называют квазиравномерным распределением. Случайная величина, имеющая квазиравномерное распределение в интервале [0, 1], принимает значения z = i/(2n — 1) с вероятностями pi = 1/2n, i = = 0, …, 2n — 1. В результате математическое ожидание квазиравномерной случайной величины совпадает с математическим ожиданием равномерной случайной последовательности интервала [0, 1], а дисперсия отличается множителем (2n + 1)/(2n — 1), который при достаточно больших n близок к единице. Кроме того, для получения значений z используют формулы (алгоритмы), поэтому такие детерминированные последовательности чисел называют псевдослучайными.
В нашем случае требуется последовательность из примерно 2105 случайных чисел. Такой объем псевдослучайных чисел с определенным числом разрядов без повторений обеспечивает стандартный датчик случайных чисел random, имеющийся в большинстве языков и сред программирования. С целью улучшения качества последовательностей после генерирования партии заготовок применяется метод возмущений, программно реализованный в виде команды randomize. Эта функция позволяет избежать повторения результатов при многократных запусках программы.
Экспериментальные исследования установили, что между некоторыми амплитудами гармоник имеются значимые корреляционные связи. Для случайных погрешностей х и у с разными функ-
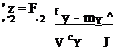 |
|||
циями распределения F(x), F2(y), математическими ожиданиями mx, my и среднеквадратическими отклонениями сх су целесообразно перейти к равномерно распределенным в интервале [0, 1] случайным величинам, воспользовавшись преобразованиями:
В этом случае коэффициент линейной корреляции находят по формуле [64]
При таком определении коэффициента корреляции упрощается решение задачи генерирования коррелированных случайных величин с разными законами распределения и исключается зависимость значения r от вида этих законов.
Воспользуемся последовательностью получения пары коррелированных случайных чисел с разными законами распределения, изложенной в работе [65]. На первом этапе генерируют три некоррелированных случайных числа А, В, С с равномерным распределением в интервале [0, 1]. Далее из них формируют пару коррелированных между собой чисел по формулам
у = ЛІГ* + BJ1-1 r*|;
![]() 11 V v (6.18) + 1-1 r* |.
11 V v (6.18) + 1-1 r* |.
Для выражений (6.18) можно строго доказать, что коэффициентом корреляции между случайными величинами yi и у2 является r*, если значение г* определялось обычным образом. Числа у1 и у2 в общем случае распределены по симметричному трапецеидальному закону с большим s1 =^| r* | + ^/1-1 r* | и ма
Далее выполняют преобразование трапецеидального распределения чисел у1 и у2 в равномерное на интервале [0, 1] по следующим формулам:
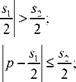 |
||
— если у, > sx/2, то при р = s2 — yi
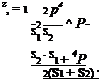 |
|
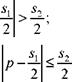 |
|
— если у, < s1/2, то при р = у,
В результате получаем случайные числа z1 и z2, равномерно распределенные в интервале [0, 1] и имеющие, как показала соответствующая численная проверка, коэффициент корреляции |r|, связанный с |r*| соотношением
|r*| = |r| + 0,005086 + 0,01739sin(6,3986|r| + 5,9575). (6.21)
Таким образом, чтобы найти требуемое значение коэффициента корреляции r между случайными величинами z1 и z2, необходимо при формировании случайных чисел у1, у2 задать величину |r*| по выражению (6.21). Абсолютная систематическая погрешность значения r при этом методе получения двух коррелированных выборок не превышает 0,0025.
При перестановках в формулах (6.18) двух пар параметров А и В, А и С случайные величины z1 и z2 будут иметь коэффициент корреляции 1 — |r|, что позволит сформировать выборки двух случайных величин с коэффициентом корреляции ±(1 — |r|) и произвольными законами распределения.
Суммируемые случайные погрешности можно разделить на некоррелированные между собой группы трех типов: включающие любое число некоррелированных погрешностей; жестко коррелированных между собой погрешностей с r = ±1 относительно какой-либо одной погрешности из этой группы, принятой за базовую; погрешностей с коэффициентом корреляции пар относительно одной базовой погрешности ±r и ±(1 — |r|). Групп второго и третьего типов может быть несколько, а значение r в каждой из них — произвольным. Если количество погрешностей в группе больше двух, то накладываются ограничения на перекрестные коэффициенты корреляции. Например, нельзя одновременно задать значения r12 = 1 и r13 = 1, если r23 Ф 1.
Для генерирования случайных чисел с заданным законом распределения используем метод инверсии, заключающийся в формировании последовательности случайных чисел z,, равномерно распределенных в интервале [0, 1], и последующем преобразовании:
X=F -‘(z,-), (6.22)
где F-1(z,) — функция, обратная функции распределения случайной величины X,.
Количество случайных чисел, используемых для получения статистически устойчивой оценки параметров при реализации на ЭВМ, колеблется в широких пределах в зависимости от объекта моделирования, оцениваемых параметров, необходимой точности и достоверности результатов моделирования.
Приближенное число испытаний при моделировании методом Монте-Карло определим по формуле
где ґдУ, n_i — коэффициент для вычисления двустороннего доверительного интервала математического ожидания; e — допустимая ошибка при оценке а.
Для определения допустимой погрешности e воспользуемся неравенством Чебышева, согласно которому для любого распределения с конечным математическим ожиданием М и дисперсией а2 по крайней мере [1 — (1/k2)]100 % значений случайной величины находится в интервале М ± ka. Пределы по данному выражению задаются с очень большим запасом. Считая, что не менее 99 % числа испытаний должны попасть в интервал М ± 3а, принимаем максимально допустимую ошибку e при оценке М в 0,2а. Максимальное среднеквадратическое отклонение для амплитуд гармоник составляет 0,1 мкм, поэтому назначаем e = 0,02 мкм. При 99%-ном доверительном уровне и ориентировочном числе испытаний n = 200 получаем *ду, „_1 = 2,601. Число испытаний по формуле (6.23) равно n = 169. Принимаем число заготовок в партии при моделировании m = 200. Тогда с 99%-ной вероятностью не менее 99 % от числа испытаний при моделировании попадет в интервал (0,1 ± 0,06) мкм.
Экспериментальные исследования выявили, что амплитуды а гармоник распределены по закону Пирсона первого типа (бета-распределение), а начальные фазы ф — по закону равной вероятности.
Функция плотности вероятности ^-распределения амплитуд гармоник имеет вид
где Г — гамма-функция; n, М — параметры ^-распределения; х — случайная величина.
Гамма-функция имеет вид
Г(у) = JхY-1e-xdx. (6.25)
0
Функция распределения начальных фаз гармоник имеет вид
F (х) = (х — а) / (b — а), (6.26)
где а, b — границы интервала изменения начальной фазы ф.
Поскольку a = 0°, b = 360°, имеем следующее выражение для функции распределения начальных фаз:
F(x) = x /360. (6.27)
В общем случае, зная плотность вероятности f х), необходимо выбрать случайное число z, и решить относительно х, интегральное уравнение:
x
![]() j f(xi) dxi = zi,
j f(xi) dxi = zi,
a
где a — наименьшее значение x,.
Для равномерного распределения обратная функция имеет явный вид, и преобразование случайной величины z, в случайную величину xi осуществляют по выражению
x = 360z,. (6.29)
Методика получения случайных величин, имеющих различные законы распределения, с помощью нормированных случайных величин изложена в работах [64, 67].
Параметры ^-распределения п и ц, полученные в результате статистической обработки экспериментальных данных, имеют нецелые значения. Поэтому применим следующий метод генерации. Вычислим
S = z11/п, S2 = zf, (6.30)
где z1, z2 — независимые друг от друга равномерно распределенные случайные числа.
Если S1 + S2 > 1, то возьмем еще одну пару случайных чисел z1, z2 и проделаем те же операции. Если S1 + S2 < 1, то
Полученные по формулам (6.25)-(6.31) распределения являются нормированными, т. е. находятся в интервале [0, 1]. По-
лучить распределения в интервале [аь а2] можно с помощью последующего преобразования:
На основе разработанного алгоритма (рис. 6.9), формул (6.16)-(6.32) и экспериментальных данных проведено моделирование критерия точности базирования для партии из 200 заготовок для бесцентрового суперфиниширования [66]. Статистическая обработка результатов показала, что наилучшим образом критерий K описывается нормальным законом при суперфинишировании. Функция плотности вероятности в этом случае однозначно определена двумя параметрами — математическим ожиданием m и среднеквадратическим отклонением а.
По результатам статистического моделирования рассчитаны первые четыре статистические момента (m1, m2, m3, m4), среднеквадратическое отклонение а, показатели асимметрии а3 и эксцесса а4 для распределения критерия K, которые приведены в табл. 6.3. Параметр наладки станка а имеет тот же смысл, что и ранее.
|
Таблица 6.3 Начальные моменты распределения критерия K в партии заготовок
|
Анализ табл. 6.3 показал, что все варианты характеризуются положительным показателем асимметрии и показателем эксцесса, равным 3 и более. При суперфинишировании наиболее нерациональный угол а = 15° (МО погрешности базирования равно 1,4 мкм и СКО равно 0,351 мкм). При наилучшем угле наладки а = 45° МО уменьшается примерно в 2,3 раза и СКО — в 2,5 раза. Столь большие различия статистических оценок критерия K по
сравнению со шлифованием объясняются тем, что оптимальный вариант наладки находится вне исследуемого диапазона угла а = 15.. .45°. При наличии ограничений на максимальное значение угла а уменьшение МО и СКО составит примерно 50 %.
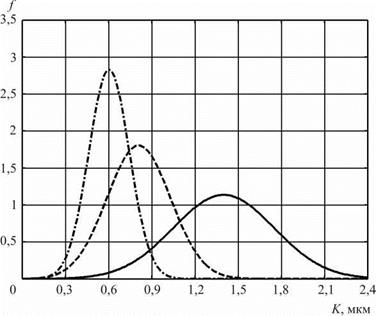
Графики плотности вероятности f соответственно для трех рассчитанных вариантов наладки изображены на рис. 6.10.
|
Рис. 6.10. Плотность вероятности критерия K в зависимости от наладки станка: сплошная линия — а = 15°; штриховая — а = 30°; штрихпунктирная — а = 45° |
Сравнение оценок математического ожидания для критерия базирования с величиной отклонения от круглости показало, что оптимальные варианты наладки шлифовального и суперфинишного станков способствуют активному исправлению профиля поперечного сечения. Кроме того, наименьшему математическому ожиданию также соответствует наименьшее среднеквадратическое отклонение (имеют единый минимум).
Для оценок математического ожидания и среднеквадратического отклонения целесообразно вычислить доверительные интервалы. В случае нормально или асимптотически нормально распределенных величин при больших выборках и неизвестных параметрах распределения (определяемых по эмпирическим данным) используют, согласно работе [68], следующие формулы. Доверительный интервал для математического ожидания т, отвечающий доверительной вероятности р = 1 — q/100:
![]() а а
а а
т — tq~i=7, т + tM==T Vn -1 ып -1
где tq — критерий Стьюдента (прир = 0,95 имеем tq = 1,960).
Доверительный интервал для математического ожидания т, отвечающий доверительной вероятности р = 1 — q/100 при нормальном распределении:
при асимптотически нормальном распределении
Результаты расчета доверительных интервалов по формулам (6.33)-(6.35) для данных из табл. 6.3 приведены в табл. 6.4.
Доверительные интервалы для распределения
критерия K в партии заготовок
|
Таблица 6.4
|
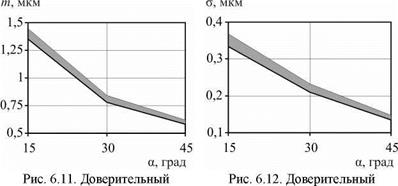
Графическая интерпретация доверительных интервалов результатов моделирования при бесцентровом суперфинишировании представлена на рис. 6.11 — для математического ожидания, на рис. 6.12 — для среднеквадратического отклонения.
|
|
интервал для математического интервал для среднеквадрати-
ожидания ческого отклонения
Анализ табл. 6.4 показал, что с уменьшением точечных оценок математического ожидания и среднеквадратического отклонения уменьшается и величина доверительных интервалов для этих параметров.