
Налаживать бесцентровые шлифовальные и суперфинишные станки на обработку одной конкретной заготовки нецелесообразно, а в партии от
клонения формы заготовок имеют стохастический характер. Выявить одну доминирующую гармонику не всегда возможно, как правило, имеются несколько гармоник со сравнительно большими амплитудами. Для решения подобных задач предназначен метод статистического моделирования, так же называемый методом статистических испытаний Монте-Карло [55]. Он базируется на применении случайных чисел некоторой случайной величины с заданным распределением вероятности. Сущность метода статистического моделирования сводится к построению моделирующего алгоритма, его реализации с помощью программно-технических средств ЭВМ и обработке данных методами математической статистики.
Применительно к задаче базирования основная идея метода Монте- Карло заключается в моделировании стохастических входных данных (отклонений формы заготовок), многократной реализации аналитической модели базирования и получении вероятностных характеристик, численные значения которых совпадают с результатом решения детерминированной задачи. В результате получают серию частных значений искомой погрешности базирования, статистическая обработка которых дает сведения о влиянии параметров наладки станка при обработке партии заготовок. Исходные данные о погрешностях формы заготовок устанавливают экспериментальным путем, а затем находят законы и параметры распределения (см. п. 7.4). Если количество реализаций достаточно велико, то полученные результаты моделирования приобретают статистическую устойчивость и с достаточной точностью принимаются в виде оценок искомых параметров. Моделирующий алгоритм приведен на рис. 6.9.
|
Рис. 6.9. Моделирующий алгоритм для наладки станка при обработке партии заготовок |
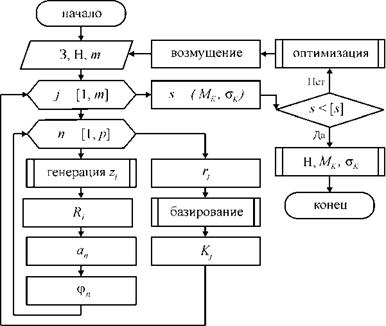
Исходными данными при моделировании являются: параметры заготовки З (радиус r0, число n гармоник, параметры распределения и границы интервала амплитуд и начальных фаз гармоник), параметры наладки станка (углы базирующих элементов, радиусы валков) и количество m заготовок в партии. Число m заготовок в партии назначают, исходя из трудоемкости моделирования, а не из реального технологического процесса. Очевидно, что с увеличением число реализаций m возрастает точность и достоверность получаемых статистических оценок.
Первый этап — генерирование последовательности случайных равномерно распределенных чисел z, для каждой заготовки в партии в зависимости от числа гармоник профиля. Полученные числа zt преобразуют в требуемый закон распределения для амплитуды а, и начальной фазы ф, каждой гармоники. В результате формируется профиль одной заготовки rj.
На втором этапе рассчитывают погрешность базирования для каждой заготовки по аналитической модели, описанной в п. 5.1 — 5.3, и находят критерий точности базирования Kj.
На третьем этапе проводят статистическую обработку критерия K, вычисленного для всех заготовок в партии. В результате получают математическое ожидание МК и среднеквадратическое отклонение ак для критерия K. Сравнивая их с допустимыми значениями [МК] и [ак], принимают решение о необходимости оптимизации наладочных параметров станка.
Для генерирования случайных чисел с заданным законом распределения используется метод инверсии [55], заключающийся в формировании последовательности случайных чисел z,, равномерно распределенных в интервале [0, 1], и последующем преобразовании:
Л-,. = Fzt), (6.17)
где Fl(z) — функция, обратная функции распределения случайной величины Л,.
Результаты статистического моделирования существенно зависят от качества исходных последовательностей случайных чисел. На практике используют три основных способа генерации случайных чисел: аппаратный (физический), табличный (файловый) и алгоритмический (программный). Достоинства и недостатки трех перечисленных способов получения случайных чисел представлены в табл. 6.1.
Из табл. 6.1. видно, что алгоритмический способ генерации случайных чисел наиболее рационален при моделировании на компьютере. Равномерно распределенная случайная величина в интервале [0, 1] имеет маЛ
тематическое ожидание m = 1А и дисперсию а = 1/12. Получить непрерывное распределение на ЭВМ невозможно, поэтому используют дискретную последовательность 2n случайных чисел того же интервала. Такой закон распределения называют квазиравномерным распределением. Случайная величина, имеющая квазиравномерное распределение в интервале [0, 1], принимает значения zt = i/(2” — 1) с вероятностями pi = 1/2”, i = 0, …, 2” — 1. В результате математическое ожидание квазиравномерной случайной величины совпадает с математическим ожиданием равномерной случайной последовательности интервала [0, 1], а дисперсия отличается множителем (2” + 1)/(2” — 1), который при достаточно больших n близок к единице. Кроме того, для получения значений zi используют формулы (алгоритмы), поэтому такие детерминированные последовательности чисел называют псевдослучайными.
Таблица 6.1
Сравнительный анализ способов генерации случайных чисел [55]
|
Способ |
Достоинства |
Недостатки |
|
аппаратный |
1) запас чисел не ограничен 2) расходуется мало операций вычислительной машины 3) не занимает место в памяти вычислительной машины |
1) требуется периодическая проверка 2) нельзя воспроизводить последовательности 3) используется специальное устройство 4) необходимы меры по обеспечению стабильности |
|
табличный |
1) требуется однократная проверка 2) можно воспроизводить последовательности |
1) запас чисел ограничен 2) занимает много места в оперативной памяти или необходимо время на обращение к внешней памяти |
|
алгоритмический |
1) требуется однократная проверка 2) можно многократно воспроизводить последовательности 3) занимает мало места в памяти машины 4) не используются внешние устройства |
1) запас последовательности чисел ограничен ее периодом 2) существенные затраты машинного времени |
В нашем случае требуется последовательность из примерно 2-105 случайных чисел. Такой объем псевдослучайных чисел с определенным числом разрядов без повторений обеспечивает стандартный датчик случайных чисел random, имеющийся в большинстве языков и сред программирования. С целью улучшения качества последовательностей после генерирования партии заготовок применяется метод возмущений, программно реализованный в виде команды randomize. Эта функция позволяет избежать повторения результатов при многократных запусках программы.
Экспериментальные исследования установили, что между некоторыми амплитудами гармоник имеются сильные корреляционные связи. Для
|
S2 — S1 + 4P 2(S1 + S2 ) ’ |
случайных погрешностей x и у с разными функциями распределения F(x), F2(y), математическими ожиданиями mx, my и среднеквадратическими отклонениями ах оу целесообразно перейти к равномерно распределенным в интервале [0, 1] случайным величинам, воспользовавшись преобразованиями:
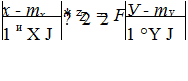
![]()

(6.18)
Для выражений (6.20) можно строго доказать, что коэффициентом корреляции между случайными величинами у1 и у2 является r*, если значение г* определялось обычным образом. Числа у1 и у2 в общем случае распределены по симметричному трапецеидальному закону с большим
если Уі < S1/2, то при р = у7
В результате получаем случайные числа z1 и z2, равномерно распределенные в интервале [0, 1] и имеющие, как показала соответствующая численная проверка, коэффициент корреляции |г|, связанный с |r*| соотношением
|r*| = |r| + 0,005086 + 0,01739sin(6,3986|r| + 5,9575). (6.23)
Таким образом, чтобы найти требуемое значение коэффициента корреляции r между случайными величинами z1 и z2, необходимо при формировании случайных чисел y1, y2 задать величину |r*| по выражению (6.23). Абсолютная систематическая погрешность значения r при этом методе получения двух коррелированных выборок не превышает 0,0025.
При перестановках в формулах (6.20) двух пар параметров А и В, А и С случайные величины z1 и z2 будут иметь коэффициент корреляции 1 — |r|, что позволяет сформировать выборки двух случайных величин с коэффициентом корреляции +(1 — |r|) и произвольными законами распределения.
Суммируемые случайные погрешности можно разделить на некоррелированные между собой группы трех типов: включающие любое число некоррелированных погрешностей; жестко коррелированных между собой погрешностей с r = +1 относительно какой-либо одной погрешности из этой группы, принятой за базовую; погрешностей с коэффициентом корреляции пар относительно одной базовой погрешности +r и +(1 — |r|). Групп второго и третьего типов может быть несколько, а значение r в каждой из них — произвольным. Если количество погрешностей в группе больше двух, то накладываются ограничения на перекрестные коэффициенты корреляции. Например, нельзя одновременно задать значения r12 = 1 и r13 = 1, если r23 Ф 1.
Количество случайных чисел, используемых для получения статистически устойчивой оценки параметров при реализации на ЭВМ, колеблется в широких пределах в зависимости от объекта моделирования, оцениваемых параметров, необходимой точности и достоверности результатов моделирования.
Приближенное число испытаний при моделировании методом Монте-Карло определим по формуле из работы [56]:
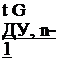 I — — Й
I — — Й
![]()
![]()
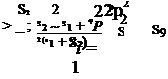 |
|
(6.18)
где t’дУ, n -1 — коэффициент для вычисления двустороннего доверительного интервала для математического ожидания; e — допустимая ошибка при оценке G.
Для определения допустимой погрешности e воспользуемся неравенством Чебышева, согласно которому для любого распределения с конечным математическим ожиданием М и дисперсией а по крайней мере [1 — (1/к)]100 % значений случайной величины находится в интервале М + ка. Пределы по данному выражению задаются с очень большим запасом. Считая, что не менее 99 % числа испытаний должны попасть в интервал М + 3а, принимаем максимально допустимую ошибку e при оценке М в 0,2а. Максимальное среднеквадратическое отклонение для амплитуд гармоник составляет 0,1 мкм, поэтому назначаем e = 0,02 мкм. При 99 %- ном доверительном уровне и ориентировочном числе испытаний n = 200, получаем їду, n. 1 = 2,601. Число испытаний по формуле (6.18) равно n = = 169. Принимаем число заготовок в партии при моделировании m = 200. Тогда с 99 %-ной вероятностью не менее 99 % от числа испытаний при моделировании попадет в интервал 0,1 + 0,06 мкм.
Экспериментальные исследования (см. п. 7.4) выявили, что амплитуды а гармоник распределены по закону Пирсона первого типа (Р — распределение) или логнормальному закону, а начальные фазы ф — по закону равной вероятности.
Функция плотности вероятности Р-распределения имеет вид:
![]()
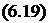
![]() Г( р + д) Г( р)Г(д)
Г( р + д) Г( р)Г(д)
где Г — гамма-функция; р, д — параметры Р-распределения; x — случайная величина.
Известная гамма-функция:
ад
Г(у) = | x ‘^e^dx.
0
Функция распределения начальных фаз гармоник имеет вид:
F(x) = (x — a)/(b — а),
где a, b — границы интервала изменения начальной фазы ф.
Так как а = 0°, b = 360°, то имеем следующее выражение для функции распределения начальных фаз:
F(x) = xt/ 360. (6.21)
В общем случае, зная плотность вероятности f(x), требуется выбрать случайное число zt и решить относительно xi интегральное уравнение:
xi
j f(x,)dxi = z,,
a
где a — наименьшее значение xt.
Для равномерного распределения обратная функция имеет явный вид, и преобразование случайной величины Zi в случайную величину xt осуществляют по выражению:
x = 360z. (6.22)
Методика получения случайных величин, имеющих различные законы распределения, с помощью нормированных случайных величин изложена в работах [56, 57].
Параметры P-распределения ц и ц, полученные в результате статистической обработки экспериментальных данных, имеют нецелые значения. Поэтому применим метод генерации, предложенный в работе [57]. Вычислим
![]() О _ _1 / Ц О _ _1 / Ц S1 Z1 , «
О _ _1 / Ц О _ _1 / Ц S1 Z1 , «
где z, z2 — независимые друг от друга равномерно распределенные случайные числа.
Если S + S2 > 1, то возьмем еще одну пару случайных чисел z, z2 и проделаем те же операции. Если S + S2 < 1, то
Полученные по формулам (6.23) — (6.26) распределения являются нормированными, то есть находятся в интервале [0, 1]. Получить распределения в интервале [a, а2] можно с помощью последующего преобразования:
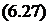 у — а
у — а
i
а2 — ах
На основе разработанного алгоритма (рис. 6.9), формул (6.19) — (6.27) и экспериментальных данных из п. 7.4 проведено моделирование критерия точности базирования для партии из 200 заготовок для трех случаев: бесцентрового шлифования с продольной подачей, бесцентрового шлифования с поперечной подачей и бесцентрового суперфиниширования. Статистическая обработка результатов показала, что наилучшим образом критерий К описывается нормальным законом при преимущественном P — распределении амплитуд гармоник (бесцентровое шлифование с продольной подачей и бесцентровое суперфиниширование) и логнормальным законом — при преимущественном логнормальном распределении амплитуд гармоник (бесцентровое шлифование с поперечной подачей). В обоих случаях функция плотности вероятности однозначно определена двумя параметрами — математическим ожиданием m и среднеквадратическим отклонением а.
Рассчитанные первые четыре статистических момента (m, m2, m3, m4), среднеквадратическое отклонение а, показатели асимметрии а3 и эксцесса а4 для распределения критерия К для бесцентрового шлифования и суперфиниширования приведены в табл. 6.2. Параметр наладки станка а имеет тот же смысл, что и ранее.
Анализ табл. 6.2 показал, что все варианты характеризуются поло
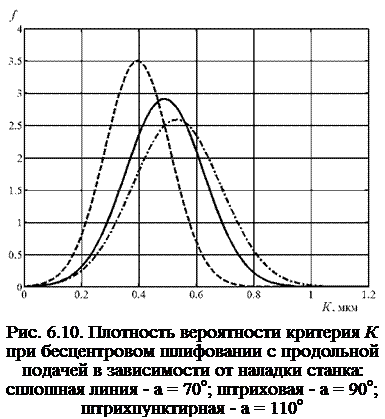
жительным показателем асимметрии и показателем эксцесса, равным трем и более. При бесцентровом шлифовании с продольной подачей наиболее нерациональный угол а = 110°, ему соответствует математическое ожидание погрешности базирования, равное 0,531 мкм, и среднеквадратическое отклонение 0,154 мкм. При наилучшем угле наладки а = 90° среднеарифметическое и среднеквадратическое отклонения уменьшаются на 26 %.
При бесцентровом шлифовании с поперечной подачей наиболее нерациональный угол а = 50°, при котором математическое ожидание погрешности базирования равно 0,46 мкм и среднеквадратическое отклонение 0,267 мкм. При наилучшем угле наладки а = 80° среднеарифметическое отклонение уменьшается на 21 % и среднеквадратическое отклонение — на 15 %.
Таблица 6.2
|
Начальные моменты распределения критерия К в партии заготовок
|
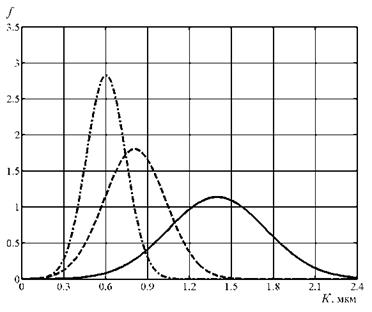
При бесцентровом суперфинишировании наиболее нерациональный угол а =15° (математическое ожидание погрешности базирования равно 1,4 мкм и среднеквадратическое отклонение 0,351 мкм). При наилучшем угле наладки а = 45° среднеарифметическое отклонение уменьшается примерно в 2,3 раза и среднеквадратическое отклонение — в 2,5 раза. Столь большие различия статистических оценок критерия К по сравнению с бесцентровым шлифованием объясняются тем, что оптимальный вариант наладки находится вне исследуемого диапазона угла а = 15… 45°.
Графики плотности вероятности f для трех рассчитанных вариантов наладки изображены на рис. 6.10 — 6.12 соответственно. Критерий К распределен при бесцентровом шлифовании с продольной подачей и суперфинишировании по нормальному закону, а при шлифовании с поперечной подачей — по логнормальному закону.
 |
Сравнение оценок математического ожидания для критерия базирования с величиной отклонения от круглости показало, что оптимальные варианты наладки шлифовального и суперфинишного станков способствуют активному исправлению профиля поперечного сечения. Кроме того, наименьшему математическому ожиданию также соответствует наименьшее среднеквадратическое отклонение.
/
|
Рис. 6.12. Плотность вероятности критерия К при бесцентровом суперфинишировании в зависимости от наладки станка: сплошная линия — а = 15°; штриховая — а = 30°; штрихпунктирная — а = 45° |
Проведенные исследования позволяют сделать вывод о том, что бесцентровые шлифовальные и суперфинишные станки целесообразно налаживать на обработку определенных партий заготовок со стохастическими отклонениями формы по критерию точности микробазирования с использованием статистического моделирования Монте-Карло.